
字符串匹配的意思是给一个字符串集合,和另一个字符串集合,看这两个集合交集是多少。
- 若是都只有一个字符串,那么就看其中一个是否包含另外一个;
- 若是父串集合(比较长的,被当做模板)的有多个,子串(拿去匹配的)只有一个,就是问这个子串是否存在于父串之中;
- 若是子串父串集合都有多个,那么就是问交集了。
KMP算法
KMP算法是用来处理一对一的匹配的。
朴素的匹配算法,或者说暴力匹配法,就是将两个字符串从头比到尾,若是有一个不同,那么从下一位再开始比。这样太慢了。所以KMP算法的思想是,对匹配串本身先做一个处理,得到一个next数组。这个数组是做什么用的呢?next [j] = k,代表j之前的字符串中有最大长度为k 的相同前缀后缀。记录这个有什么用呢?对于ABCDABC这个串,如果我们匹配ABCDABTBCDABC这个长串,当匹配到第7个字符T的时候就不匹配了,我们就不用直接移到B开始再比一次,而是直接移到第5位来比较,岂不美哉?所以求出了next数组,KMP就完成了一大半。next数组也可以说是开始比较的位数。
计算next数组的方法是对于长度为n的匹配串,从0到n-1位依次求出前缀后缀最大匹配长度。
比如ABCDABD这个串:
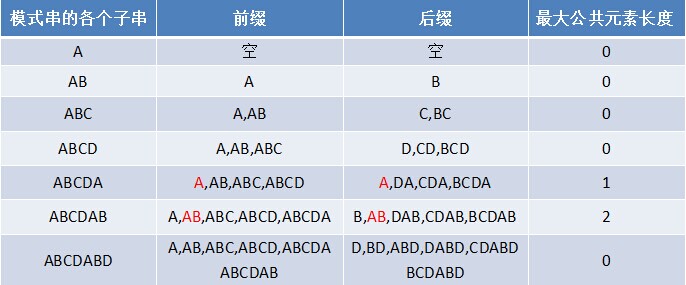
如何去求next数组呢?k是匹配下标。这里没有从最后一位开始和第一位开始分别比较前缀后缀,而是利用了next[i-1]的结果。
1 |
|
这里是按照《算法导论》的代码来写的。算法导论算法循环是从1到n而不是从0到n-1,所以在下面匹配的时候需要j=next[j+1]。
1 |
|
这里next数组的作用就显现出来了。最后返回的是i-j,也就是说,是从i位置前面的第j位开始的,也就是上面说的,next数组也可以说是开始比较的位数。也就是说,在父串的i位比的时候已经是在比子串的第j位了。
一个完整的代码:
1 |
|
字典树算法
上面的KMP是一对一匹配的时候常用的算法。而字典树则是一对多的时候匹配常用算法。其含义是,把一系列的模板串放到一个树里面,然后每个节点存的是它自己的字符,从根节点开始往下遍历就可以得到一个个单词了。
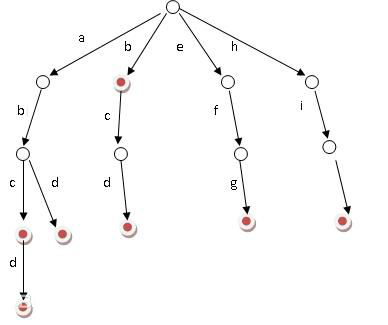
我这里写的代码稍微和上面有一点区别,我的节点tnode里面没有存它本身的字符,而是存一个孩子数组。所以当数据量很大的时候还是需要做一些变通的,不可直接套用此代码。若是想以每个节点为一个node,那么要注意根节点是空的。
树的节点tnode,这里的next[i]存的是子节点指针。sum=0表示这个点不是重点。为n>0表示有n个单词以此为终点。
1 |
|
插入函数:
假设字典树已经有了aer,现在插入abc,首先看a,不为空,那么直接跳到a节点里,看b,为空,那么新建,跳到b里,新建c,跳出。
1 |
|
字符串比较:就是一个个字符去比呗…时间复杂度O(m),m是匹配串长度。
1 |
|
给个完整的代码:
1 |
|
AC自动机
字典树是一对多的匹配,那么AC自动机就是多对多的匹配了。意思是:给一个字典,再给一个m长的文本,问这个文本里出现了字典里的哪些字。
这个问题可以用n个单词的n次KMP算法来做(效率为O(n*m*单词平均长度)),也可以用1个字典树去匹配文本串的每个字母位置来做(效率为O(m*每次字典树遍历的平均深度))。上面两种解法效率都不高,如果用AC自动机来解决的话,效率将为线性O(m)时间复杂度。
AC自动机也运用了一点KMP算法的思想。简述为字典树+KMP也未为不可。
首先讲一下acnode的结构:
与字典树相比,就多了个fail指针对吧,这个就相当于KMP算法里的next数组。只不过它存的是失配后跳转的位置,而不是跳转之后再向前跳了多少罢了。
1 |
|
插入什么的我就不说了,记得把fail置为空即可。
这里说一下fail指针的获取。fail指针是通过BFS来求的。
看这么一张图
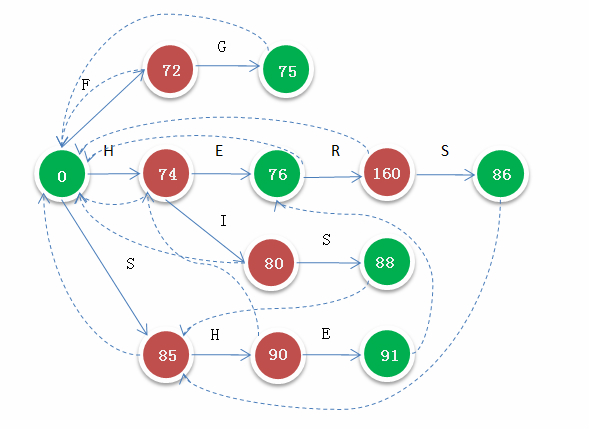
图中数字我们不用管它,绿色代表是终点,虚线就是fail指针了。我们可以看到91 E节点的fail指针是指向76 E 的,也就是说执行到这里如果无法继续匹配就会跳到76 E那个节点继续往后匹配。我们可以看到它们前面都是H,也就是说fail指针指向的是父节点相同的同值节点(根节点视为与任何节点相同)。我们要算的是在一个长文本里面有多少个出现的单词,这个fail指针就是为了快速匹配而诞生的。若文本里出现了HISHERS,我们首先匹配了HIS,有通过fail指针跳到85 S从而匹配SHE,再匹配HERS。fail指针跳到哪里就代表这一点之前的内容已经被匹配了。这样就避免了再从头重复判断的过程。
在函数里,当前节点的fail指针也会去更新此节点的孩子的fail指针,因为父节点相同啊,而且因为它是此节点的fail指针,这两个节点的父节点也相同啊~所以一路相同过来,就保证fail指向的位置前缀是相同的。
1 |
|
给个完整的代码:
1 |
|

